
在许多场景下,我们都会用到OCR,比如用手机扫描信用卡号码、识别纸质文档的文字。Dynamsoft Label Recognition (DLR)和Dynamic Web TWAIN (DWT)都具备准确的OCR功能。
虽然一般情况下,OCR能取得不错的效果,但很多时候,我们需要使用各种图像处理技术来改善结果。
增白/去除阴影
不良的照明可能会影响OCR结果。我们可以增白图像或从图像中去除阴影来改善OCR结果。
反色
浅色文字很难定位和识别,因为OCR引擎通常针对深色文本进行训练。

如果我们将其颜色反转,将更容易识别。

在DLR中,有一个GrayscaleTransformationModes参数可以用来反转颜色。
以下是JSON格式的设置模板:
"GrayscaleTransformationModes": [
{
"Mode": "DLR_GTM_INVERTED"
}
]
DLR .net版的识别结果:
缩放
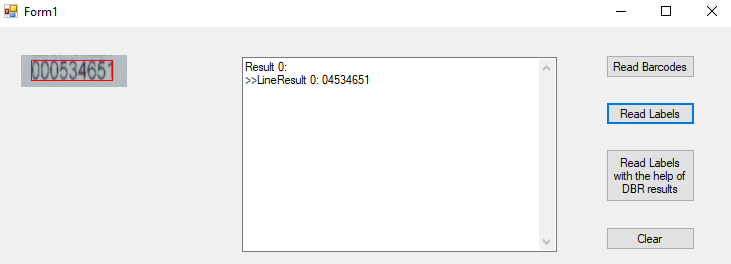
如果文字的高度太低,OCR引擎可能不会给出很好的结果。通常,图像的DPI最好有300。
DLR从1.2开始,有了一个ScaleUpModes参数用于放大文字。当然,我们也可以自己缩放图像。
直接读取图像会给出错误的结果:
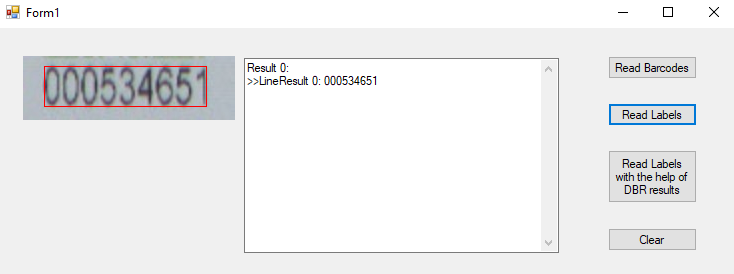
将图像放大2倍后,结果是正确的:
纠偏
如果文字有点歪斜,基本还是能够识别的。但如果过于倾斜,结果会受到很大影响。我们需要对图像进行纠偏以改善结果。
我们可以使用OpenCV的霍夫线变换进行此操作。

这是对上面的图像进行校正的代码。
#coding=utf-8
import numpy as np
import cv2
import math
from PIL import Image
def deskew():
src = cv2.imread("neg.jpg",cv2.IMREAD_COLOR)
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
kernel = np.ones((5,5),np.uint8)
erode_Img = cv2.erode(gray,kernel)
eroDil = cv2.dilate(erode_Img,kernel) # erode and dilate
showAndWaitKey("eroDil",eroDil)
canny = cv2.Canny(eroDil,50,150) # edge detection
showAndWaitKey("canny",canny)
lines = cv2.HoughLinesP(canny, 0.8, np.pi / 180, 90,minLineLength=100,maxLineGap=10) # Hough Lines Transform
drawing = np.zeros(src.shape[:], dtype=np.uint8)
maxY=0
degree_of_bottomline=0
index=0
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(drawing, (x1, y1), (x2, y2), (0, 255, 0), 1, lineType=cv2.LINE_AA)
k = float(y1-y2)/(x1-x2)
degree = np.degrees(math.atan(k))
if index==0:
maxY=y1
degree_of_bottomline=degree # take the degree of the line at the bottom
else:
if y1>maxY:
maxY=y1
degree_of_bottomline=degree
index=index+1
showAndWaitKey("houghP",drawing)
img=Image.fromarray(src)
rotateImg = img.rotate(degree_of_bottomline)
rotateImg_cv = np.array(rotateImg)
cv2.imshow("rotateImg",rotateImg_cv)
cv2.imwrite("deskewed.jpg",rotateImg_cv)
cv2.waitKey()
def showAndWaitKey(winName,img):
cv2.imshow(winName,img)
cv2.waitKey()
if __name__ == "__main__":
deskew()
检测到的线段:
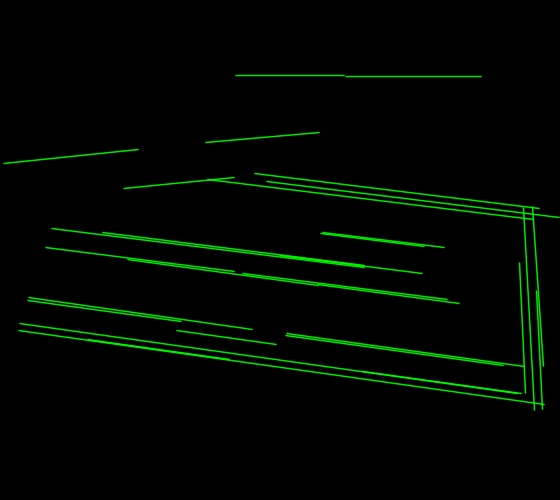
去倾斜后的:

但是对于下图,很难确定旋转角度是否应加上180。

默认的旋转结果:

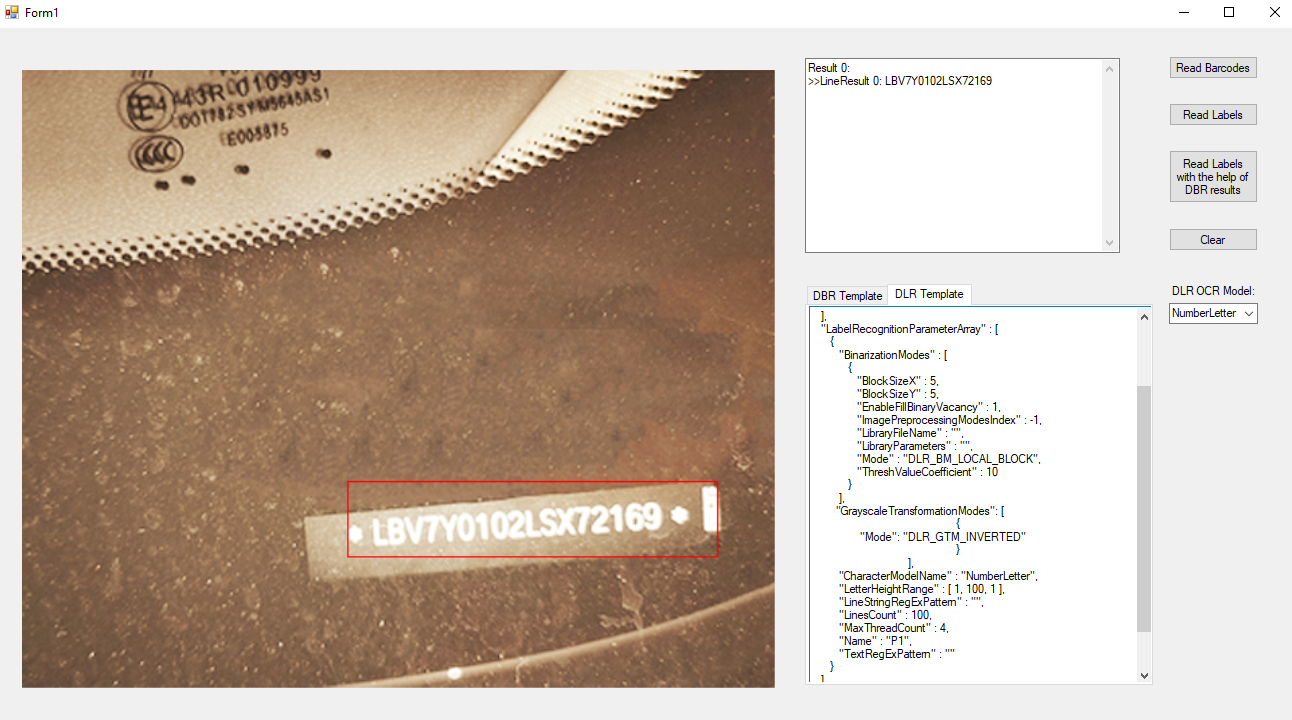
文本与条码存在对应关系,我们可以使用Dynamsoft Barcode Reader读取条码并获得正确的旋转度数。
使用在线条码demo,我们可以看到条码读取结果中包含检测到的角度。
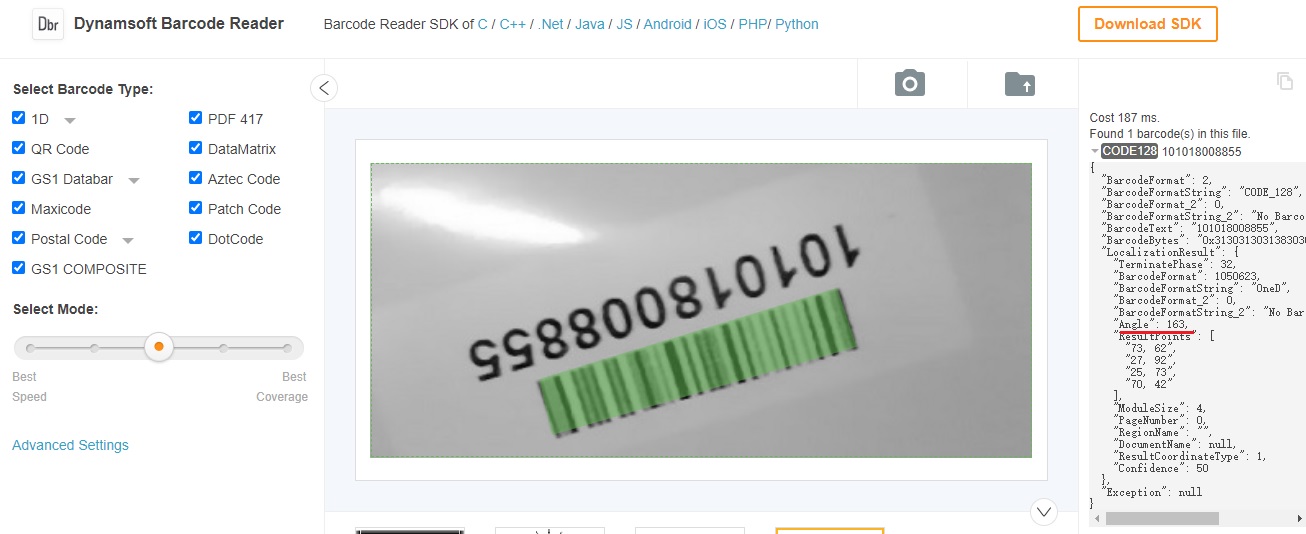
然后我们可以正确地旋转图像。

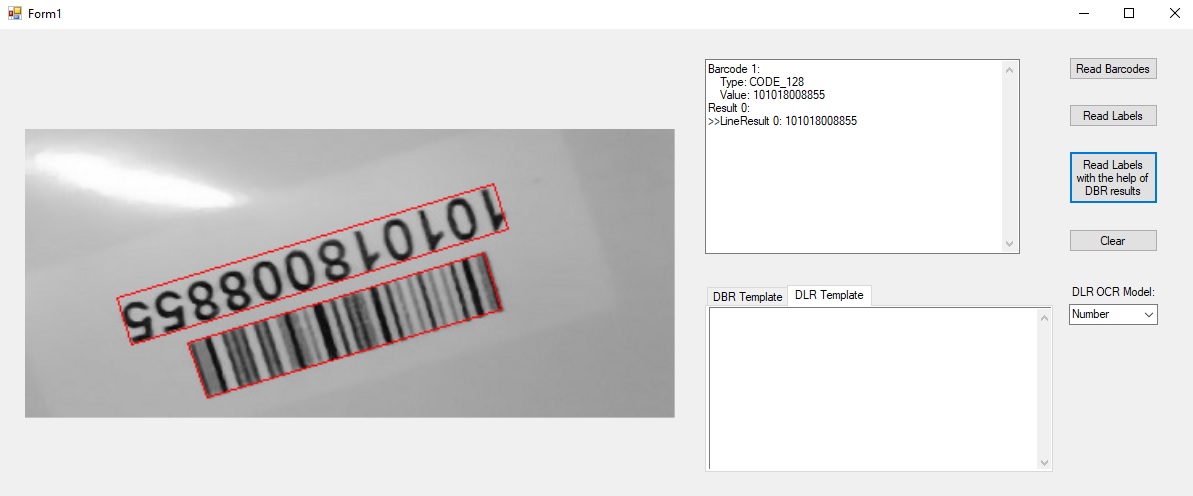
我们可以将DBR和DLR搭配起来以识别文字。这篇文章分享了如何结合DBR和DLR来读取条码附近的文本。
结果:
联系支持人员
如果尝试这些处理方法后仍有问题,请联系我们以获得帮助。