
简介
在文档电子化的过程中,常常需要从获取的图像文件中提取出需要的信息。这个过程中,最准确的方式是用机器思考的方式进行,典型的做法是识别二维码获取内容。如果您的文档满足这个条件,可以参考[二维条码识 别](../Dev-Guide/Barcode-Reader.md)。实际应用中,一般获取的图像中包含的信息是以人类思考的方式展现的,即文字。这种情况下,要让机器读懂并提取信息,就要用到**光学字符识别技术**(英语: Optical Character Recognition,OCR)。本文中我们探讨一下如何快速的实现在浏览器中扫描并识别文字。
环境要求
-
通过npm下载本文使用的核心控件
npm install dwt@14.0.3然后在这个目录可以看到
-
进入目录node_modules\dwt\samples 下
可以看到
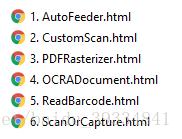
-
在本文中,我们要重点研究的是 OCRADocument.html。直接双击打开。在浏览器中按照提示安装控件
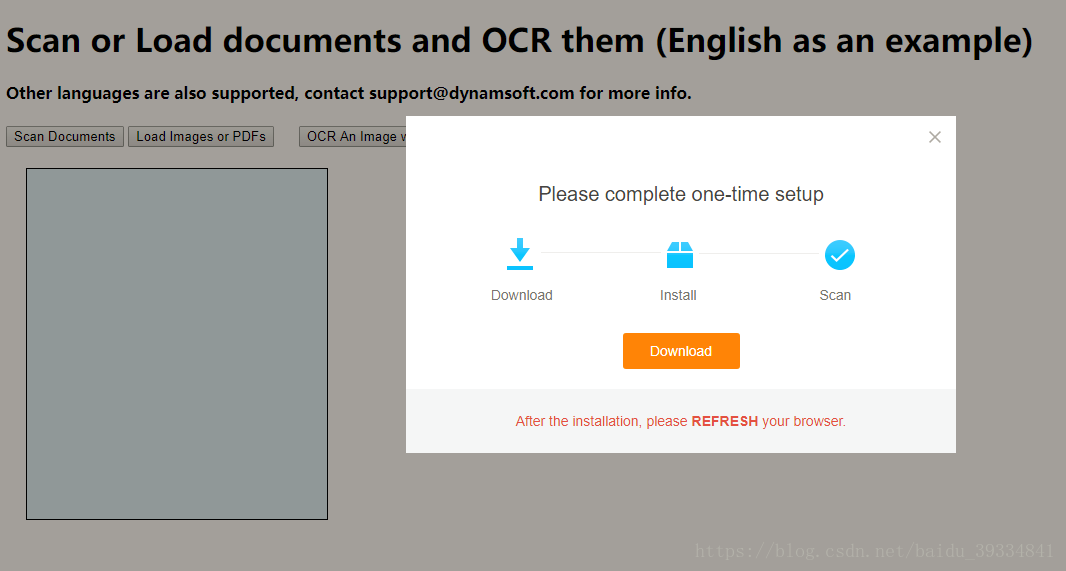
正常情况下,安装的文件可以在 C:\Windows\SysWOW64\Dynamsoft\DynamsoftService 目录中找到。这里的核心文件主要是:DynamsoftService.exe, dwt_trial_14.0.0.0618.dll, DynamicOCR.dll。
-
安装完成后
刷新页面,点击第一(本地需要有扫描仪)或者第二按钮来扫描或者加载本地图片文件。由于该控件开发者是加拿大公司,相关页面是英文显示,且默认只能识别英文。所以我们加载一个英文文件并点击“OCR An Image with English”。图片的识别结果就在右面的结果框中显示出来了。是不是很简单?

如果需要了解更多技术细节,可以直接看 OCRADocument.html 的JS源码。也可以直接联系免费快速的中国区技术支持
如果你看到以下提示则表示你用的授权过期了。
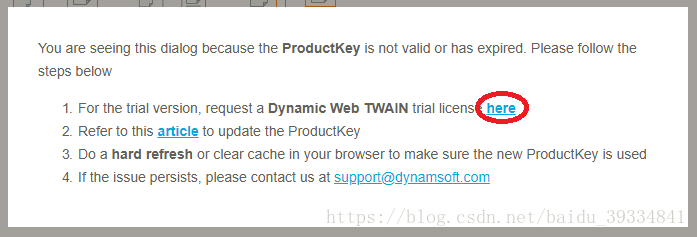
解决方案为点击上图中标红的链接,获取一个新的授权并加上下面的代码中的第一句(在window.onload回调函数中)
Dynamsoft.WebTwainEnv.ProductKey = "<新的授权>"; Dynamsoft.WebTwainEnv.Load();